|
はじめに |
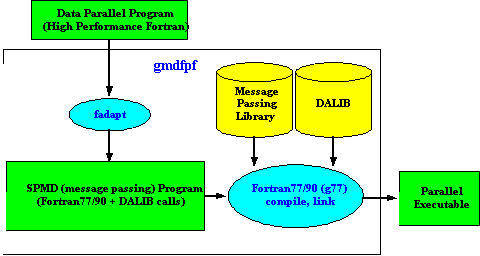
ADAPTOR (Automatic DAta Parallelisim TranslatOR) はGMD (Berman National Research Center for Infomation Technology)のSCAI(Institute for Algorithms and Scientific Computing of the CMD)が開発した、HPF2.0(High Performance Fortran)互換のコンパイラです。HPFの本質的な考え方は、局所性抽出のためのデータ分割をユーザが明示的に指示し、それ以外の仕事をコンパイラに任せようとするものであり、これにより、ユーザは煩わしいプログラムのSPMD (Single Program Multiple Data Stream)化や通信管理から開放され、従来のFortranプログラミングと非常に親和性の高い方法で分散メモリ・システムを利用することが可能となります。ADAPTORコンパイラは、HPFで記述されたプログラムをMPI(Message Passing Interface)などの標準並列化ライブラリを用いたSPMDプログラム(Fortran77/90のソースコード)に変換するものです。 ADAPTORは大きくわけて以下の3つのパッケージで構成されています。
ユーザの設定 |
ログインシェルがbashの場合
export PHOME=/usr/local/adaptor export PATH=$PHOME/bin:$PATH export MANPATH=$PHOME/man:$MANPATH |
ログインシェルがcsh/tcshの場合
setenv PHOME /usr/local/adaptor setenv PATH $PHOME/bin:$PATH setenv MANPATH $PHOME/man:$MANPATH |
HPFのプログラミング例 |
簡単な例を用いて、HPFプログラミングとADAPTORの使い方について説明する。HPF言語の最大の特徴は、配列データの分散メモリへの配置指定の機能である。ユーザは、この機能を用いてデータアクセス局所性の抽出、つまり分散メモリプログラミングにおいて、最も重要な通信の最適化をコンパイラに対して間接的に指示することができる。以下のサンプルプログラムを見てみよう。
program example1
parameter(n = 100000)
real x(n), dot
!hpf$ processors p(4)
!hpf$ distribute x(block) onto p
do i=1,n
x(i)=1.0e0/float(i)
end do
dot=0.0e0
do i=1,n
dot=dot+x(i)*x(i)
end do
print *, 'dot = ',dot
stop
end
|
本プログラムは、配列データの2乗和を求めるものである。最初のループで配列Xの初期値が設定され、その次のループにおいて、x(i)の2乗を変数dotに足し込んでいる。HPFプログラミングの中心は、主要配列に対するデータマッピングの指定である。規則(定型)的な計算パターンを持つプログラムならば、データマッピングだけ指定すれば、これだけで並列化がうまくいくケースがかなりある。
上記のプログラムにおいては、HPF指示文を2行挿入するだけでよい。最初の指示文は4の抽象プロセッサPの宣言であり、次の指示文は配列Xを4つのブロックに分割して、Pのそれぞれに割り当てることを指示している。
次のこのプログラムをADAPTORを使ってコンパイルしてみよう。
並列処理する実行ファイルを作成する場合、
gmdhpf -v -o example1 example1.hpf |
1nodeで処理する実行ファイルを作成する場合、
gmdhpf -v -1 -o example1 example1.hpf |
となる。
ドキュメント |